Свяжитесь с нами
Открыты для сотрудничества с яркими инициативными командами.
Открыты для сотрудничества с яркими инициативными командами.
Открыты для сотрудничества с яркими инициативными командами.
Открыты для сотрудничества с яркими инициативными командами.
Как использовать Phi-3 и Gemma для маршрутизации запросов и вызова инструментов вместо дорогого GPT-4.
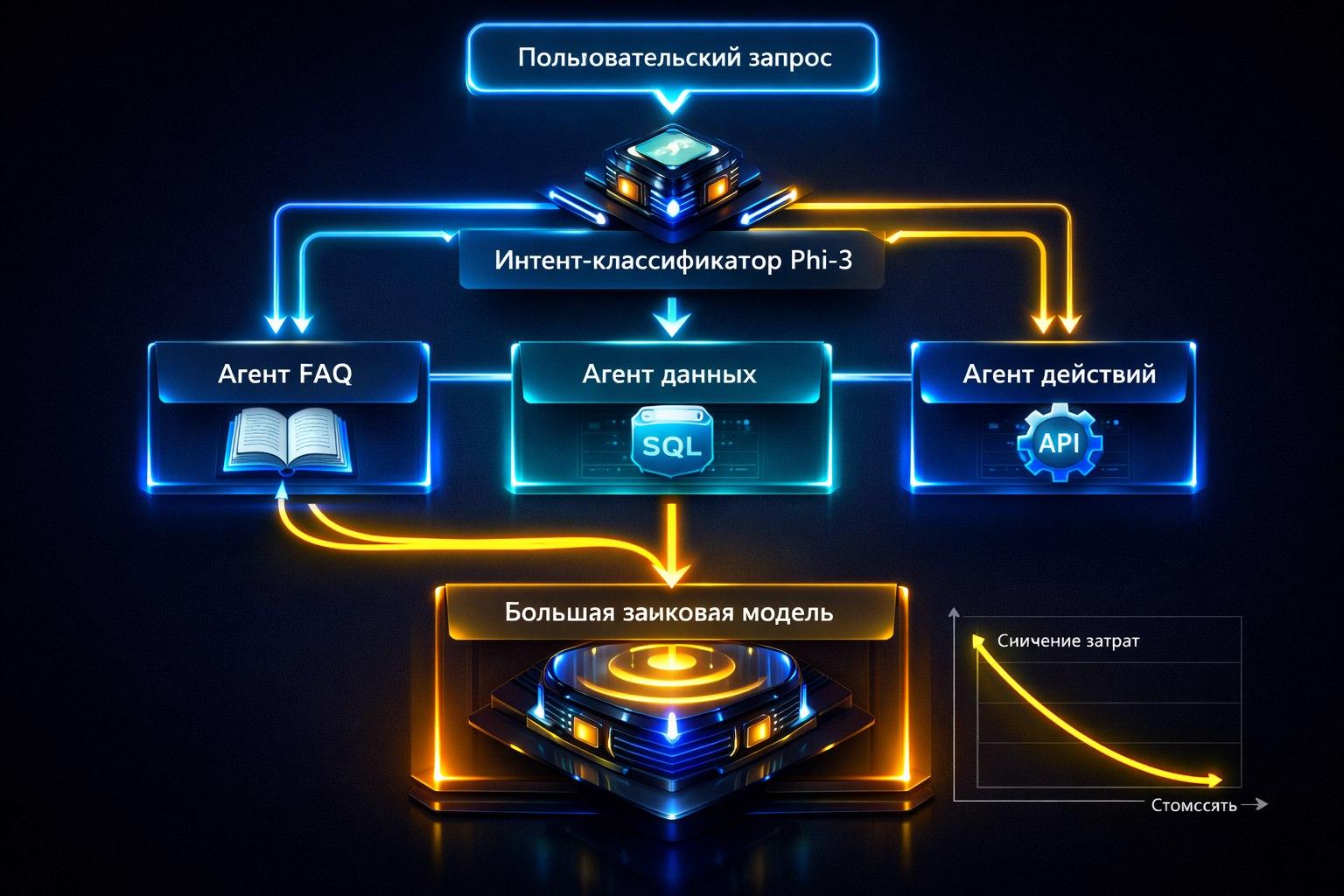
Большие LLM (GPT-4, Claude) — это "мозг" агента, который дорого обходится. Но в архитектуре агента много рутинной работы, которую можно поручить маленьким, специализированным моделям. Это снижает стоимость и latency системы в десятки раз.
Проблема: Агент на большой модели — это финансовый ад
Представьте агента, который обрабатывает 1000 запросов в час. Каждый запрос — это диалог с LLM (планирование + выполнение). При цене $0.01 за 1K выходных токенов GPT-4, счет будет астрономическим. При этом 80% запросов — простые и могут быть решены по шаблону.
Решение: Многоуровневая архитектура с маленькими моделями
Уровень 1: Детерминированный фильтр (Не AI)
Задача: Отсечь очевидные запросы, которые можно обработать по правилам (regular expressions, keyword matching).
Пример: Запросы "как сбросить пароль?" -> сразу показать статью из базы знаний.
Уровень 2: Классификатор/Маршрутизатор (Маленькая LLM, 1B-3B)
Задача: Определить сложность запроса и тип необходимого агента.
Модель: Phi-3-mini или Gemma 2B, дообученная на классификацию.
Как работает:
Получает запрос пользователя.
Относит его к одному из классов: [simple_faq, data_lookup, complex_reasoning, creative_task, code_generation].
Маршрутизирует запрос дальше.
Промпт-шаблон: Classify user query: "{query}". Categories: simple_faq, data_lookup, complex_reasoning, creative, code. Respond ONLY with the category name.
Уровень 3: Специализированные "исполнители" (Маленькие или средние LLM, 3B-7B)
Для каждой категории — свой оптимизированный агент.
Агент simple_faq (Модель 1B-3B):
Задача: Найти ответ в базе знаний (RAG) и сформулировать его.
Промпт простой: Answer the question based only on context: {context}. Question: {query}.
Особенность: Этому агенту не нужно "рассуждать", только искать и пересказывать. Маленькой модели хватит.
Агент data_lookup (Модель 3B-7B с tool calling):
Задача: Выполнить конкретное действие: поиск в БД, расчет, получение статуса.
Модель: Gemma 7B или Phi-3-mini, дообученная на вызов инструментов (tool calling).
Как обучать: Нужен датасет вида: [{"query": "Какая температура в Москве?", "tool_call": {"name": "get_weather", "args": {"city": "Moscow"}}}].
Инференс: Модель генерирует структурированный вызов API, который система выполняет.
Агент complex_reasoning (Большая модель 70B или GPT-4):
Задача: Только действительно сложные запросы, требующие анализа, планирования, творчества.
Ключевой момент: Этот дорогой ресурс используется только в 5-20% случаев, что делает систему экономически жизнеспособной.
Техническая реализация: Tool Calling для маленьких моделей
Большие модели умеют вызывать инструменты "из коробки". Маленькие нужно дообучать.
Формат данных для обучения: Превратите вызов инструмента в текстовый шаблон, который модель должна выучить.
Human: Закажи пиццу с пепперони на адрес ул. Ленина, 10.
Assistant: <tool_call>
{
"name": "order_pizza",
"arguments": {
"type": "pepperoni",
"address": "ул. Ленина, 10"
}
}
</tool_call>
Fine-tuning: Обучите модель (например, Gemma 2B) на таких примерах. Она научится завершать ответ после Assistant: нужным XML/JSON-блоком.
В продакшне: Ваш код просто парсит этот блок и выполняет вызов API.
Преимущества подхода:
Стоимость: Основной трафик идет через дешевые модели. Экономия 10-50x.
Latency: Маленькие модели отвечают за 50-200 мс, что критично для интерактивных чатов.
Надежность: Поведение маленьких, fine-tuned моделей более предсказуемо, чем большой многозадачной LLM.
Безопасность: Узкоспециализированного агента проще проверить на вредоносные действия.
Пример архитектуры чат-бота для интернет-магазина:
Пользователь: «Хочу отследить заказ №12345 и узнать про доставку холодильников.»
Маршрутизатор (Phi-3-mini): Классифицирует запрос как [order_status, product_info] (мульти-интент!).
Оркестратор: Запускает двух агентов параллельно:
Агент данных (Gemma 2B): Вызывает get_order_status(12345).
Агент FAQ (TinyLlama): Ищет в RAG информацию о доставке крупной техники.
Агрегатор результатов: Получает ответы от обоих агентов и формирует финальное сообщение: «Ваш заказ №12345 в пути. Доставка холодильников занимает 3-5 дней, требуется предварительный звонок.»
Вывод:
Не используйте большую LLM как единственный "мозг" для всего. Декомпозируйте задачу агента на уровни. Маленькие модели — идеальные "диспетчеры" и "исполнители" для шаблонных операций. Оставьте большую модель для действительно сложных кейсов. Такой подход — признак зрелой, экономически эффективной и отказоустойчивой AI-архитектуры.