Свяжитесь с нами
Открыты для сотрудничества с яркими инициативными командами.
Открыты для сотрудничества с яркими инициативными командами.
Открыты для сотрудничества с яркими инициативными командами.
Открыты для сотрудничества с яркими инициативными командами.
Как превратить набор скриптов в управляемую, масштабируемую и прибыльную AI-платформу. Архитектура следующего поколения для продакшн-сред.
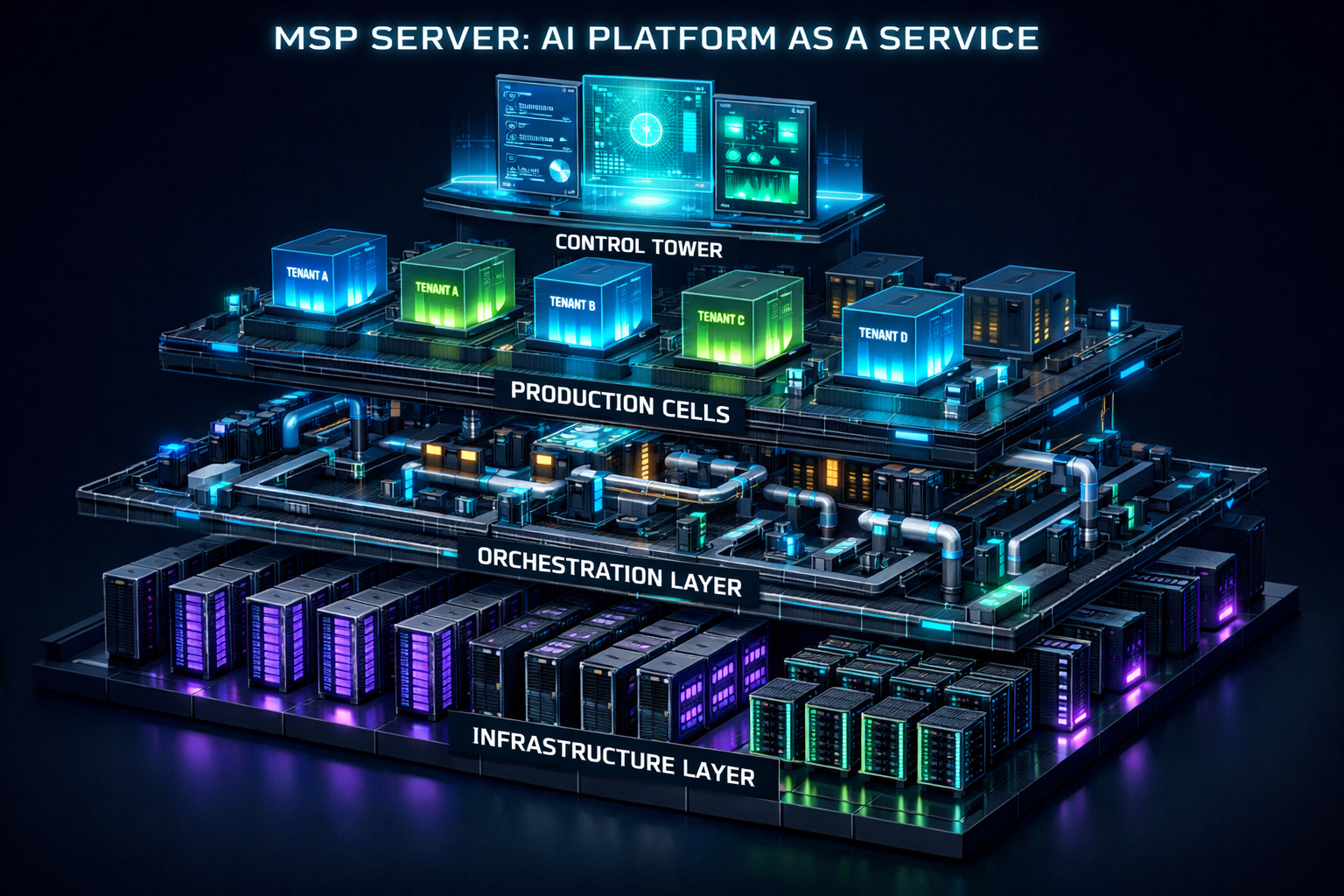
Вы создали рабочий прототип — RAG-ассистент, аналитик документов или AI-агент. Он запускается с вашего ноутбука и даже работает на демо. Но путь от прототипа до коммерческого продукта, который обслуживает сотни клиентов, требует принципиально иной архитектуры. Вам нужен MSP Server (Managed Service Provider Server) — не просто сервер, а целая операционная система для запуска и управления множеством изолированных AI-инстансов.
Типичные ошибки при масштабировании:
«Монолит на стероидах»: Одна огромная модель пытается обслуживать всех клиентов, смешивая их данные и контексты.
Административный кошмар: Обновление промпта или модели для одного клиента требует развертывания для всех.
Нулевая изоляция: Проблема с производительностью у одного клиента «валит» всех остальных.
Непрозрачная экономика: Невозможно точно посчитать стоимость инфраструктуры и вычислительных ресурсов на одного клиента (tenant).
MSP Server решает это, внедряя принципы мультитенантности, контейнеризации и оркестрации в мир LLM.
1. Жесткая изоляция тенантов (Tenant Isolation)
Каждый клиент (арендатор) получает собственный, изолированный набор ресурсов:
Векторная БД на тенанта: Отдельный namespace или полная инстанция (например, отдельный кластер Qdrant или индекс в Pinecone).
Выделенные вычислительные мощности: Группы GPU/CPU, закрепленные за конкретным тенантом через механизмы Kubernetes (node pools, taints/tolerations).
Собственные конфигурации: Уникальные промпт-шаблоны, модели, параметры инференса (temperature, max_tokens), правила модерации.
2. Управление артефактами как кодом (Infrastructure as Code для AI)
Конфигурация каждого AI-инстанса описывается в декларативном формате (YAML):
yaml
tenant_id : "acme_corp"
llm_instance :
base_model : "mistralai/Mistral-7B-Instruct-v0.3"
quantization : "fp8"
prompt_version : "v2.1.legal"
rag_config :
embedding_model : "intfloat/multilingual-e5-large"
chunk_size : 1024
reranker : "cross-encoder/ms-marco-MiniLM-L-6-v2"
resources :
guaranteed_gpu : 1
memory_limit : "16Gi"
Это позволяет запускать инстансы в одну команду, версионировать конфигурации и применять GitOps-практики.
3. Динамическая оркестрация и экономика ресурсов (Dynamic Orchestration)
Горячий и холодный пулы: Часто используемые инстансы клиентов находятся в «горячем» состоянии (модель загружена в память). Реже используемые — в «холодном» (образ сохранен в реестре, запускается по первому запросу с задержкой).
Автомасштабирование на уровне инстансов: Если инстанс тенанта не справляется с нагрузкой, MSP Server автоматически разворачивает его реплику.
Гранулярный биллинг: Система точно учитывает потребление GPU-секунд, объем обработанных токенов, запросы к векторной БД и хранилищу для каждого клиента.
4. Централизованный контроль и наблюдаемость (Centralized Control Plane)
Единая админ-панель (Control Plane) предоставляет обзор всей платформы:
Дашборд эксплуатации: Здоровье всех инстансов, утилизация ресурсов (GPU, память, сеть).
Дашборд экономики: Себестоимость и доходность каждого тенанта, прогноз расходов.
Центр обновлений: Массовое, выборочное или канареечное (canary) обновление базовых моделей, эмбеддинг-моделей или промптов для групп клиентов.
| Компонент | Задача | Примеры технологий |
|---|---|---|
| Оркестратор | Управление жизненным циклом изолированных инстансов | Kubernetes (K8s) с кастомными операторами |
| Сетевой шлюз | Маршрутизация запросов к правильному тенанту, аутентификация, лимиты | Envoy, Traefik, Kong с кастомными плагинами |
| Хранилище артефактов | Версионирование образов моделей, промптов, конфигов | Docker Registry, Hugging Face Hub, S3-совместимое хранилище |
| Векторная БД | Мультитенантное хранилище эмбеддингов | Weaviate (multi-tenancy), Qdrant (отдельные кластера), Pinecone (индексы) |
| Инференс-сервер | Высокоэффективный запуск моделей | vLLM, TensorRT-LLM, TGI (Text Generation Inference) |
| Мониторинг | Сбор метрик по тенантам | Prometheus + Grafana (с метками tenant_id), OpenTelemetry |
| Биллинг и учет | Трекинг потребления | Собственный микросервис + интеграция с Stripe, YooKassa |
Заявка (Onboarding): Клиент через портал или API отправляет запрос на создание инстанса, загружает свои данные (документы, базу знаний).
Подготовка (Provisioning):
Система создает namespace в K8s.
Запускает Data Pipeline для обработки данных клиента: чанкование, генерация эмбеддингов, загрузка в выделенную векторную БД.
Создает Docker-образ с заданной моделью и конфигурацией.
Разворачивает инстанс в кластере с заданными ресурсами.
Тестирование (Smoke Test): Автоматически запускаются тестовые запросы к новому инстансу для проверки работоспособности.
Ввод в эксплуатацию (Go-Live): Инстанс помечается как активный, сетевой шлюз начинает направлять к нему трафик с конкретным API-ключом.
SaaS (Software as a Service): Клиент платит ежемесячную подписку за доступ к вашему AI-продукту.
PaaS (Platform as a Service): Клиент (более технический) арендует изолированную AI-платформу, чтобы развернуть свою собственную модель и логику.
Инфраструктура по запросу: Предоставление GPU-кластера с предустановленным стеком LLM-инструментов для внутренних команд компании.
MSP Server — это не затраты, а стратегическая инвестиция. Он превращает ваш AI-проект из рискованного эксперимента с непредсказуемой масштабируемостью в предсказуемый, прибыльный и управляемый облачный продукт. Вы получаете контроль, изоляцию, детальную аналитику и возможность предлагать индивидуальные условия разным клиентам.
Постройте MSP Server — и вы построите не просто сервер, а фабрику по производству AI-решений, где каждый новый клиент — это не техническая головная боль, а новый конвейер, который можно запустить нажатием кнопки.