Свяжитесь с нами
Открыты для сотрудничества с яркими инициативными командами.
Открыты для сотрудничества с яркими инициативными командами.
Открыты для сотрудничества с яркими инициативными командами.
Открыты для сотрудничества с яркими инициативными командами.
От дата-озера хаоса к озерному дому порядка. Как построить единую платформу для аналитики, ML и работы с текстами/изображениями.
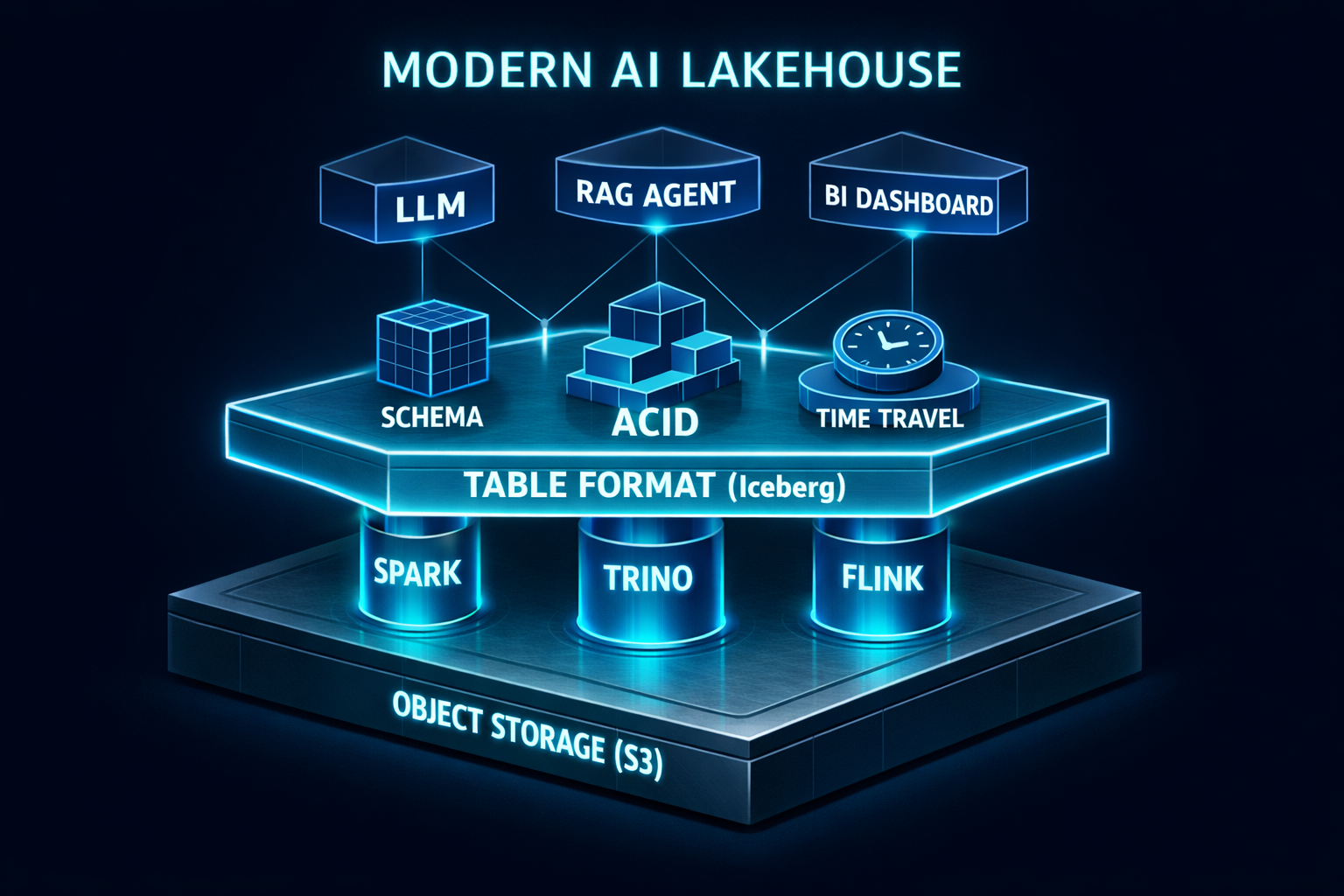
У вас есть Data Lake (озеро) в S3 — свалка всех данных: логи, JSON от API, выгрузки из БД, PDF-документы, картинки. Аналитики не могут с этим работать, модели обучаются неделями, а для нового AI-проекта инженеры снова копируют часть данных в отдельное место. Data Lakehouse — это современная архитектура, которая решает эту проблему. Она объединяет гибкость и дешевизну хранения Data Lake с управлением, схемой и производительностью Data Warehouse, создавая идеальный фундамент для AI.
Эволюция: Lake -> Warehouse -> Lakehouse
Data Lake (Озеро, ~2010s): Хранилище «всего» в сыром виде (S3, HDFS). Плюсы: дешево, любая структура. Минусы: «болото данных» — нет транзакций, сложно обеспечить качество, медленные запросы.
Data Warehouse (Склад, ~1990s): Оптимизированное хранилище для SQL-аналитики (Snowflake, BigQuery, Redshift). Плюсы: высокая скорость, поддержка ACID. Минусы: дорого, негибко, плохо подходит для неструктурированных данных (текст, изображения).
Data Lakehouse (Озерный дом, ~2020s): Берет лучшее от обоих. Хранит все данные (структурированные и неструктурированные) в дешевом object storage (S3). Поверх накладывает слой открытых форматов таблиц (Apache Iceberg, Delta Lake, Apache Hudi) и метаданных, которые обеспечивают: ACID-транзакции, управление схемой, версионирование данных и высокую производительность запросов.
Почему Lakehouse критически важен для AI-проектов?
Единый источник для всех типов данных: В одной таблице Iceberg вы можете хранить колонки со структурированными данными (ID клиента, сумма, дата), а в другой колонке — путь к файлу в S3 (PDF-договор, изображение чека, аудиозапись разговора). Это позволяет легко строить пайплайны для извлечения признаков (фичей) как из чисел, так и из текстов/картинок.
Эффективная работа с огромными объемами: Обучение LLM или больших рекомендательных систем требует петабайтов данных. Перемещать их из озера в отдельный склад для обработки — дорого и медленно. Lakehouse позволяет запускать ML-задачи (Spark, Ray) прямо на данных в S3, без лишнего копирования.
Time Travel и воспроизводимость экспериментов: Форматы Iceberg/Delta Lake хранят снапшоты данных. Вы можете точно знать, на каком срезе данных (snapshot_id) обучалась ваша модель месяц назад, и воспроизвести этот эксперимент. Это золотой стандарт MLOps.
Быстрая аналитика поверх AI-результатов: После того как LLM обработала документы и извлекла сущности (например, компании, суммы), результаты можно записать обратно в Lakehouse как новую структурированную таблицу. И тут же аналитики могут сделать SQL-отчет по этим данным, соединив их с другими бизнес-таблицами.
Технический стек для построения Lakehouse:
Формат табличного слоя (обязательно): Apache Iceberg (нейтральный формат, набирает огромную популярность), Delta Lake (от Databricks, тесно связан с их экосистемой), Apache Hudi.
Вычислительный движок: Apache Spark (основной для ETL/ELT), Trino (для быстрых интерактивных SQL-запросов), Apache Flink (для streaming).
Каталог метаданных: AWS Glue Data Catalog, Project Nessie (каталог с версионированием для Iceberg), Hive Metastore.
Менеджер инфраструктуры: Kubernetes (для запуска всех компонентов) или платформенные решения (Databricks, AWS Lake Formation).
Практический шаблон для AI-проекта:
Сырые данные поступают в S3 в папку /raw/ (логи, документы).
Data Pipeline (на Spark) очищает, структурирует и записывает данные в таблицы Iceberg в папке /curated/. Тексты документов кладутся в колонку text_content.
Еще один пайплайн читает text_content из Iceberg, делает чанкование и эмбеддинги, и записывает векторы и метаданные в векторную БД (отдельный сервис).
AI-приложение (RAG, агент) работает с векторной БД для семантического поиска, а при необходимости тянет дополнительные структурированные контексты из таблиц Iceberg через быстрые SQL-запросы (Trino).
Вывод для архитектора платформы данных:
Data Lakehouse — это не будущее, а настоящее для компаний, серьезно занимающихся AI. Это архитектура, которая снимает барьеры между инженерами данных, Data Scientist'ами, аналитиками и ML-инженерами, давая им единую, управляемую и мощную платформу. Постройте Lakehouse — и вы построите прочный фундамент для любого AI-проекта, который придет к вам завтра.


